
ActiveRecord is an easy-to-use and powerful ORM, but it’s also easy to write inefficient code with it. Today, we’re going to identify some common issues with ActiveRecord and learn how to fix them to optimize ActiveRecord.
First things first, ensure your database is well-designed and has the necessary indexes. Without proper indexing, your efforts in ActiveRecord will hardly yield good results.
In this article, I’ll outline five key areas for improvement. But here’s the most important takeaway, even if you don’t read to the end:
Before optimizing your queries, really consider why you need the data you’re fetching. Do you actually need it? Is there another way to obtain this information? You might be surprised how often you can simplify your code and how much faster your Rails app can become by thinking this way.
Now let’s go through main problem areas.
N+1 Problem
What is the N+1 Problem?
The N+1 problem is a common issue in web development, especially when using ORMs like ActiveRecord in Rails applications. It happens when your code makes one query to retrieve records from a database and then additional queries for each record to get related data. For example, if you have 10 users and you want to get all their posts, you might end up making 1 query to get the users and 10 more queries to get the posts for each user - that’s 11 queries in total!
This is bad for two reasons:
- Performance: More queries mean more time talking to the database, which slows down your application.
- Scalability: As your data grows, the number of queries grows too, making it worse.
How to Spot the N+1 Problem
You usually find this problem during development or code review. Watch out for loops that access associated data. For example:
users = User.all
users.each do |user|
puts user.posts
end
This code is a red flag for N+1 problems. You can spot it easily in your development.log:
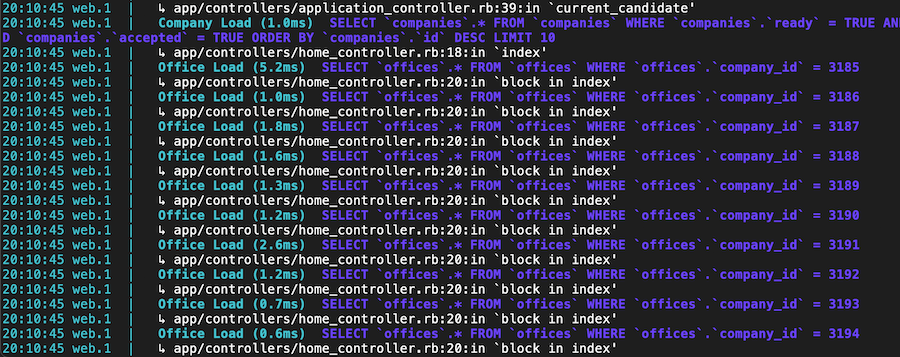
Solutions
Eager Loading with includes
Use includes to tell ActiveRecord to load associated data in advance. For our users and posts example:
users = User.includes(:posts).all
users.each do |user|
puts user.posts
end
This changes the queries: one to load users and one to load all posts for those users.
Using joins
When you need associated data for conditions but not to use the data itself, joins is more efficient than includes. It combines tables in a single query.
User.joins(:posts).where(posts: { published: true })
Bullet Gem
If you need to “automate” n+1 detection there is a good gem for that. It’s called Bullet and helps to kill N+1 queries and unused eager loading. It watches your queries and notifies you when you should add or remove includes and joins.
Select Only What’s Needed
A common issue in ActiveRecord queries is overfetching data, where you retrieve more information from the database than necessary. This can slow down your application by using extra memory and processing power.
Let’s look at the real-world example. In one of the projects I work on we have a massive AR model, each record contains a lot of data. Here are the real micro-benchmarks:
puts Benchmark.measure { VeryBigModel.last(100).to_a }
0.015937 0.000000 0.015937 ( 0.046568)
puts Benchmark.measure { VeryBigModel.select(:id, :some_other_field).last(100).to_a }
0.001363 0.000000 0.001363 ( 0.003545)
46ms is quite a lot for only 100 records. Don’t you think?
To optimize performance, it’s crucial to fetch only the columns you need from the database. ActiveRecord provides methods like select, pluck, and count for this purpose.
Using select
select allows you to specify the columns you want to retrieve. For example, if you only need the name and email of users:
User.select(:name, :email)
This generates a SQL query that only fetches the specified columns, reducing data transfer and memory usage. You will end up with a working ActiveRecord User, but the fields that were not fetched are going to be nil. So this is not perfect in many scenarios.
Using pluck
pluck is more efficient when you need values from a single column. It directly returns an array of values, bypassing the creation of ActiveRecord objects:
user_names = User.pluck(:name)
This is particularly useful for reducing memory overhead when you don’t need full model instances.
Using count or size
When you just need to count records, use count instead of loading records into memory:
active_users_count = User.where(active: true).count
This executes a COUNT query in the database, which is much faster and memory-efficient than fetching all the data from SQL and then loading records into Ruby objects.
Even better method is size, it is able to just calculate the number of records for loaded associations and run count query when needed.
Ruby on Rails Caching
Caching is everything when you are scaling up. Rails offers a few options for caching. It helps reduce the number of database queries, which can be a significant bottleneck, especially for applications with heavy read operations.
In the end the biggest performance improvement is not to do the work faster, instead it’s better not to do the work at all.
How Rails Caching Works
Rails provides two primary caching techniques:
-
Query Caching: This caches the result set of a query. When the same query is called again, it fetches the result from the cache instead of hitting the database.
-
Rails Caching: This involves various Rails caching strategies, like page, action, and fragment caching.
Using Query Caching
Query caching is automatically enabled in Rails for every controller action. For example:
class UsersController < ApplicationController
def show
@user = User.find(params[:id]) # This query is cached
# ... other code ...
@user = User.find(params[:id]) # This fetches from cache
end
end
As you can tell this is pretty weird example, becuase you should just reuse the variable, but ActiveRecord got you covered anyway.
Using Rails Caching
Rails caching is more manual but offers more control and it’s actually useful. You can cache fragments, pages, or actions. Here’s an example of fragment caching:
<% cache @user do %>
<%= render @user %>
<% end %>
This caches the rendered view of @user and serves it from cache on subsequent requests. It’s most useful if you use Rails views.
Using External Caching
Another option is to fetch data once and save it for later use, Redis is great for that as it’s great at accessing data really fast. Also it’s easy to invalidate keys. For sure it’s worth checking out.
Batch Processing of Large Data Sets
Batch processing is essential when dealing with large data sets in ActiveRecord. It allows you to handle massive amounts of records without overwhelming your server.
When you try to load a very large number of records into memory, it can lead to performance issues, including slow response times and memory bloat. For instance, loading millions of records at once for processing is not feasible in a real-world application.
Solution: ActiveRecord find_each and find_in_batches
ActiveRecord provides two methods to handle this efficiently: find_each and find_in_batches.
Using find_each
find_each retrieves a batch of records and yields each record to a block. It’s great for scenarios where you need to process each record individually:
User.find_each do |user|
# process each user
end
This method automatically handles batch loading of records in manageable chunks, typically 1000 at a time.
Using find_in_batches
find_in_batches is similar but yields batches of records, not individual ones. This is useful when you want to work with groups of records at a time:
User.find_in_batches do |users|
# process a batch of users
end
Customizing Batch Size
Both find_each and find_in_batches allow you to specify the size of each batch. For instance, if you want to process records 500 at a time:
User.find_each(batch_size: 500) do |user|
# process each user
end
Data Denormalization
Data denormalization is a strategy used in database optimization, especially relevant in the context of ActiveRecord and Rails applications. It’s about intentionally duplicating data to reduce complex queries and improve read performance. Most problems with performance start when you are trying to peform complex joins or perform some aggreggations or calculations on the fly. That’s where denormalization may be an option.
In a normalized database, data is separated into multiple related tables to reduce redundancy. However, this can lead to complex and slow queries, particularly when you need to join several tables. Denormalization simplifies this by introducing some redundancy, making data retrieval faster and easier.
When to Use Denormalization
Consider denormalization when:
- Read Performance: Your application has heavy read operations and you need to speed them up.
- Complex Joins: You’re dealing with multiple joins that slow down queries.
- Aggregated Data: You frequently query aggregated data, like counts or averages.
Cache counter example ActiveRecord
Suppose you often display the count of comments on a post. Instead of counting comments each time, store the count in a comments_count field in the posts table.
Ensure this redundant data stays accurate. You can use ActiveRecord callbacks or database triggers. For the comments example, increment comments_count in the posts table every time a comment is added.
class Comment < ApplicationRecord
belongs_to :post, counter_cache: true
end
This counter_cache option automatically updates the comments_count in the posts table when a comment is added or removed. Read more on this in the Rails docs
Considerations
- Data Integrity: Denormalization can lead to data inconsistencies. Ensure mechanisms are in place to keep data synchronized.
- Write Performance: While read performance improves, write performance can suffer because multiple records need updating.
- Complexity: Introducing denormalization adds complexity to your data model and application logic.
Conclusion
In wrapping up, ActiveRecord, while user-friendly and powerful, requires mindful coding practices to avoid inefficiency. By understanding and addressing common issues like the N+1 problem, overfetching data, and the nuances of caching, we can significantly boost the performance of our Rails applications.
Remember, the key is not always about doing the work faster; sometimes, it’s about not doing unnecessary work at all. This approach, with a few tricks mentioned in the article should setup you and your app for success. Hopefuly ;)